SAFe: Непрерывное развёртывание (Continuous Deployment), опросник
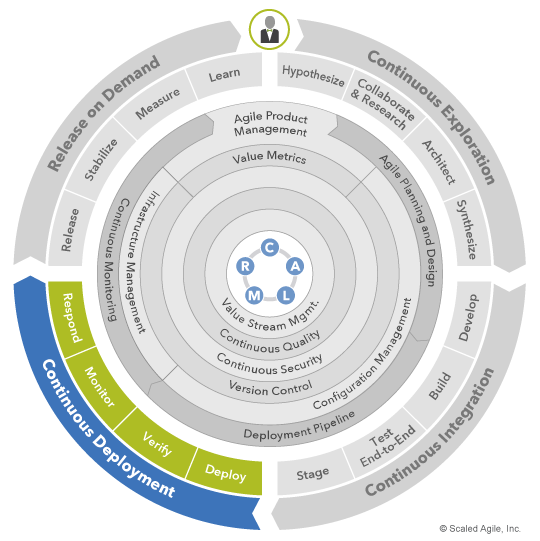
Непрерывное развертывание (Continuous Deployment, CD) — это процесс, который извлекает проверенные функции из непрерывной интеграции и развертывает их в производственной среде, где они тестируются и готовятся к выпуску. Это третий элемент в конвейере непрерывной доставки, состоящем из четырех частей: непрерывного исследования (CE), непрерывной интеграции (CI), непрерывного развертывания и выпуска по требованию.
Вопрос 1: Ускорение выхода на рынок — стратегическая цель непрерывного внедрения. Хотя непрерывное развертывание на самом деле не обеспечивает вывод функций на рынок (это задача выпуска по требованию), непрерывное развертывание имеет решающее значение для того, чтобы бизнес мог своевременно выходить на рынок, гарантируя, что ценность всегда доступна для выпуска.
Как часто ваша команда релизит новые фичи?
Сидим (1-2): Мы проводим развертывание каждые 6 месяцев или дольше.
Ползем (3-4): Мы проводим развертывание каждые 1-3 месяца.
Идем (5-6): Мы проводим развертывание каждые две недели.
Бежим (7-8): Мы внедряем развертывание каждую неделю.
Летим (9-10): Мы постоянно развертываемся.
Вопрос 2: Развертывание (деплой)
Развертывание — это фактическая миграция компонентов в производственную среду. Поскольку конвейер непрерывной доставки отделяет развертывание от выпуска, предполагается, что развернутые функции не доступны конечным пользователям. Пожалуйста, оцените способность вашей команды постоянно внедрять функции в производство, а также способность контролировать их видимость с помощью переключателей функций и других средств.
Сидим (1-2): Функции развертываются в рабочей среде каждые более 3 месяцев; развертывание выполняется вручную и болезненно; «развернуто» подразумевает «выпущено».
Ползем (3-4): Компоненты развертываются в рабочей среде на границах PI; развертывание в основном выполняется вручную; «развернуто» подразумевает «выпущено».
Идём (5-6): Функции развертываются в рабочей среде на каждой итерации; развертывания в основном автоматизированы; некоторые функции могут быть развернуты без выпуска.
Бежим (7-8): Функции развертываются в рабочей среде на каждой итерации и полностью автоматизируются по конвейеру; распространен темный запуск (dark releases).
Летим (9-10): Функции развертываются непрерывно на протяжении каждой итерации; Команды разработчиков инициируют развертывание непосредственно с помощью конвейерных инструментов; выпуск полностью отделен от развертывания; темные запуски являются нормой.
Вопрос 3: Проверка
Развертывания должны быть проверены на полноту и целостность перед выпуском конечным пользователям. Пожалуйста, оцените способность вашей команды точно определять успех или неудачу развертывания и способность выполнять откат или последующее исправление в зависимости от обстоятельств для устранения проблем с развертыванием.
Сидим (1-2): Развертывания не проверяются в рабочей среде перед выпуском конечным пользователям.
Ползем (3-4): Развертывания проверяются с помощью ручных тестов на дым и / или UAT; мы решаем проблемы с развертыванием в течение установленного льготного / сортировочного / гарантийного срока; мы часто исправляем проблемы непосредственно в процессе производства.
Идём (5-6): Развертывания проверяются с помощью ручных тестов перед выпуском конечным пользователям; откат является болезненным или невозможным; мы не вносим изменения непосредственно в процессе производства.
Бежим (7-8): Развертывания проверяются с помощью автоматических смоук-тестов, синтетических транзакций и тестов на проникновение перед выпуском; мы можем легко выполнить откат или переадресацию исправлений для восстановления после неудачных развертываний.
Летим (9-10): Автоматизированные производственные тесты выполняются на постоянной основе и используются системы мониторинга загрузки; неудачные развертывания могут быть немедленно откатаны или исправлены в дальнейшем по всему конвейеру.
Вопрос 4: Мониторинг
Мониторинг подразумевает, что телеметрия всего стека активна для всех функций, развернутых в рамках конвейера непрерывной доставки, так что производительность системы, поведение конечных пользователей, инциденты и ценность для бизнеса могут быть быстро и точно определены в процессе производства. Пожалуйста, оцените эффективность вашей команды в мониторинге всего стека решений (front-end, средний уровень, серверная часть, инфраструктура и т.д.) и способность анализировать ценность функций на основе этих событий.
Сидим (1-2): Не существует производственного мониторинга на уровне функций; существует только мониторинг инфраструктуры.
Ползем (3-4): Позволяет регистрировать только ошибки и исключения; анализ событий предполагает ручное сопоставление журналов из нескольких систем.
Идём (5-6): Функции регистрируют сбои, активность пользователей и другие события; данные анализируются вручную для расследования инцидентов и оценки бизнес-ценности функций.
Бежим (7-8): Запущен мониторинг полного стека; события могут быть соотнесены по всей архитектуре; данные представлены с помощью системных панелей мониторинга.
Летим (9-10): Федеративная платформа мониторинга обеспечивает универсальный доступ к аналитическим данным всего стека; данные используются для оценки производительности системы и ценности для бизнеса.
Вопрос 5: Восстановление
Способность обнаруживать непредвиденные производственные инциденты и восстанавливаться после них имеет решающее значение для непрерывной системы поставок. Пожалуйста, оцените эффективность вашей команды в упреждающем выявлении производственных проблем высокой степени серьезности, выявлении первопричин с помощью систем мониторинга и быстром решении проблем путем создания, тестирования и развертывания исправлений по конвейеру (по сравнению с применением изменений непосредственно в процессе производства).
Сидим (1-2): Клиенты обнаруживают проблемы раньше, чем это делаем мы; решение высокоприоритетных проблем требует много времени и реагирования; клиенты не уверены в нашей способности устранять производственные неполадки.
Ползем (3-4): Операционные проблемы связаны с производством; участие в разработке требует значительной эскалации; команды обвиняют друг друга во время кризиса.
Идём (5-6): Разработка и эксплуатация совместно управляют процессом разрешения инцидентов; восстановление после крупных инцидентов — это реактивная, но командная работа.
Бежим (7-8): Наши системы мониторинга обнаруживают большинство проблем раньше, чем это делают наши клиенты; Разработчики и оперативные службы активно работают над восстановлением после крупных инцидентов.
Летим (9-10): Наши системы мониторинга предупреждают нас об опасных состояниях на основе тщательно разработанных пороговых значений допуска; Разработчики несут ответственность за поддержку своего собственного кода и заблаговременно выпускают исправления по конвейеру до того, как это коснется пользователей.
Алексей Бушманов
Сертифицированный скрам-мастер, тренер и коуч Сфера интересов: Развитие команд и организаций, тренинги и обучение
Рекомендуем посмотреть:

7 шагов решения конфликта
03.07.2023
5 вопросов. Ретроспектива. Сбор данных
02.07.2023
Способы разрешения конфликтов
30.06.2023